
【1】 歌声データベースを作成する
【2】wavファイルからピッチデータ(dsファイル)を作成する
【3】Google colabを利用して学習する
【4】OpenUtauで音を出す
【1】 歌声データベースを作成する
DiffSingerでは歌声データ(.wav)とラベルファイル(.lab)が必要になります
MIDIやUSTは必要ありません
また、歌のピッチ補正をする必要もありません
ラベリングの方法はNNSVS/ENUNUと同じです(ここでは説明しません)
ディレクトリ構成は以下の様にしてください
キャラクター名
├─曲名1
│ ├─曲名1.wav
│ └─曲名1.lab
├─曲名2
│ ├─曲名2.wav
│ └─曲名2.lab
NNSVS/ENUNU用歌声データベースが既にある方は、それを変換することですぐにDiffsinger用データベースを作成することができます
"GlottalStop"は"q"に、"Edge"は"vf"に変換する必要があります
VS Code等のフォルダを読み込めるテキストエディタで一発変換してください
silラベルは使えないため、変換ツールsil2integrated_pauを使って消してください(カノンの落ちる城で配布しています)
【2】wavファイルからピッチデータ(dsファイル)を作成する
※注意※
この工程は飛ばしても学習可能です
品質的には次のようになります
ピッチ無編集でこの工程を行う > ピッチ補正済みでこの工程を行う > ピッチ補正済みでこの工程を飛ばす > ピッチ無補正でこの工程を飛ばす
この工程を行う場合、事前にpythonをインストールしてください(うちのバージョンは3.8くらいでした)
そもそもDiffSingerはピッチを活かさない使い方が主流のようです
(2-1) nnsvs-db-converter
https://github.com/UtaUtaUtau/nnsvs-db-converter/releases/tag/portable
ここから
nnsvs-db-converter-portable.7z
をダウンロードし、解凍します。
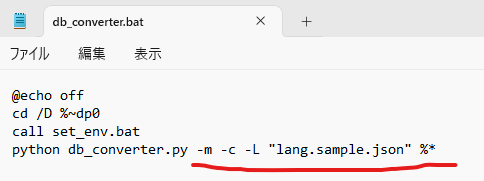
db_converter.batをテキストエディタで開き、4行目を以下のように書き換え保存します
python db_converter.py -m -c -L "lang.sample.json" %*
曲名ディレクトリをdb_converter.batへとD&Dすると、曲名ディレクトリ以下に"diffsinger_db"というフォルダが生成されます
├─曲名1
├─曲名1.wav
├─曲名1.lab
└─diffsinger_db
├─transcriptions.csv
└─wavs
├─曲名1_seg000.ds
├─曲名1_seg000.wav
├─曲名1_seg001.ds
├─曲名1_seg001.wav
上記のようなファイル構成になっていれば成功です
このまま(要検証)キャラクター名ディレクトリをzipで圧縮してDiffSinger用歌声データベースは完成です
(2-2) convert_ds.py
https://github.com/openvpi/MakeDiffSinger
ここから、緑色の[Code▼]をクリックし、Download ZIPをクリックします
zipを解凍し、variance-temp-solutionの中でコマンドプロンプトを出し、
python convert_ds.py csv2ds 曲名/diffsinger_db/transcriptions.csvのパス 曲名/diffsinger_db/wavsのパス
を実行すると曲名.wavと同じ場所に曲名.dsが生成されます
この説明伝わる?
├─曲名1
├─曲名1.wav
├─曲名1.lab
├─曲名1.ds ←NEW!
└─diffsinger_db
├─transcriptions.csv
└─wavs
├─曲名1_seg000.ds
├─曲名1_seg000.wav
├─曲名1_seg001.ds
├─曲名1_seg001.wav
この作業を曲数回繰り返します
「python convert_ds.py csv2ds 」まで入力した後に、パスを入力したいディレクトリやファイルをDOS窓にD&Dすることで楽できます
(2-3)slurcutter
https://github.com/openvpi/MakeDiffSinger/releases/tag/v0.0.1-slurcutter-v0.0.1.2
ここからSlurCutter.0.0.1.3.zipをダウンロードし解凍します
SlurCutter 0.0.1.3\bin\SlurCutter.exeをダブルクリックで起動します
File→OpenFolderで曲名ディレクトリを開きます
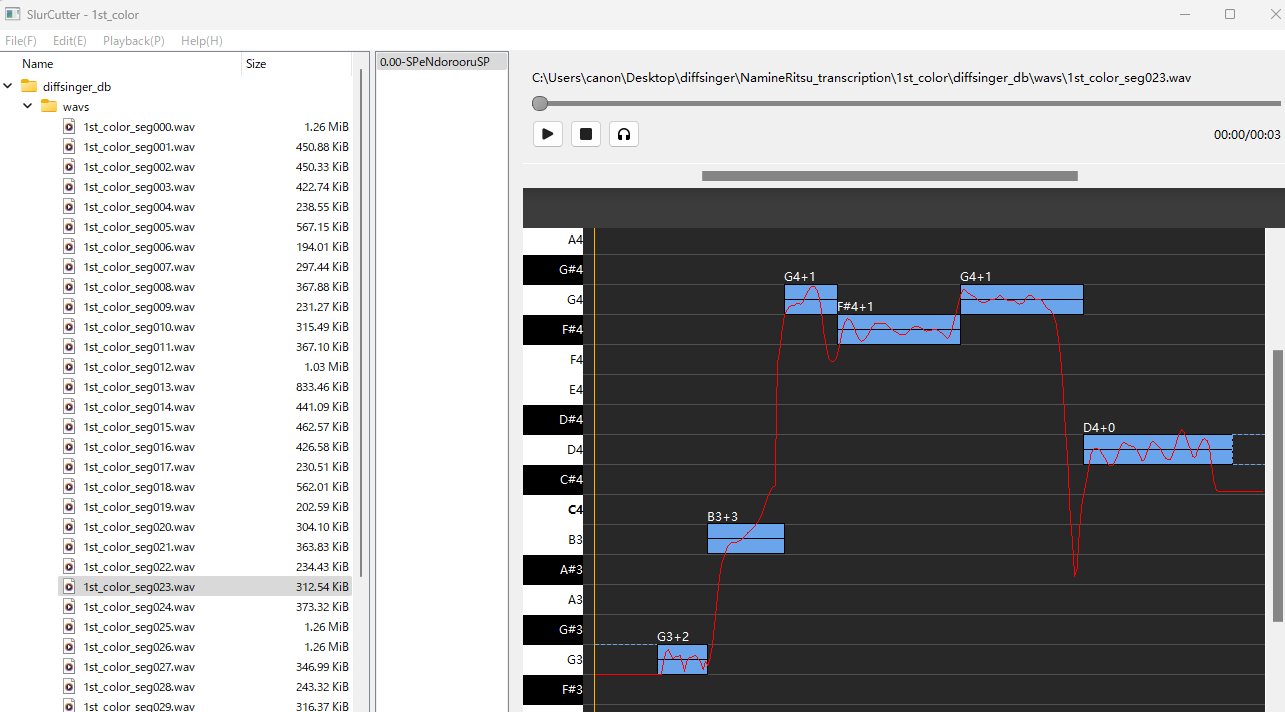
左の窓でwavsフォルダを選び、曲名_segXXX.wavを選びます
青い四角のノートを適切な音程に修正していきます(最初から大体あっています)
選択ファイルを切り替えると自動で保存されます
【3】 Google colabを利用して学習する
ローカルのやり方は知りません、知ってる方教えてください
※GoogleDriveの容量が鬼のように減っていきます。10GBくらいは空いてないと危ない
GoogleDriveの中にdiffsinger用のフォルダを作成し、作成した歌声DB(zip形式)を入れます
ここでは以下のような構成をおススメします
今後はそれ前提で話を進めますので事前にこの通りにフォルダ制作をして歌声DBを入れておいてください
diffsinger(フォルダ)
├─歌声DB.zip
├─acoustic(フォルダ)
└─variance(フォルダ)
https://colab.research.google.com/github/MLo7Ghinsan/DiffSinger_colab_notebook_MLo7/blob/main/DiffSinger_colab_notebook.ipynb
にアクセスします
(3-1)acousticモデルの作成
・Setupをクリック
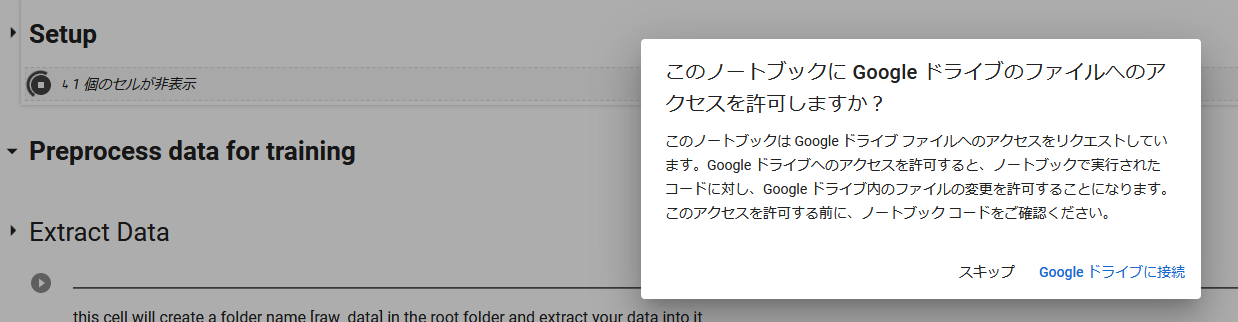
すぐにGoogleDriveの認証が入るので、出た窓に従って操作してください
そのあとはしばらく待ちます(ここは結構時間がかかります)
終わった後に声が出るので、音を出してるとめちゃびびります
・Extract Dataの設定
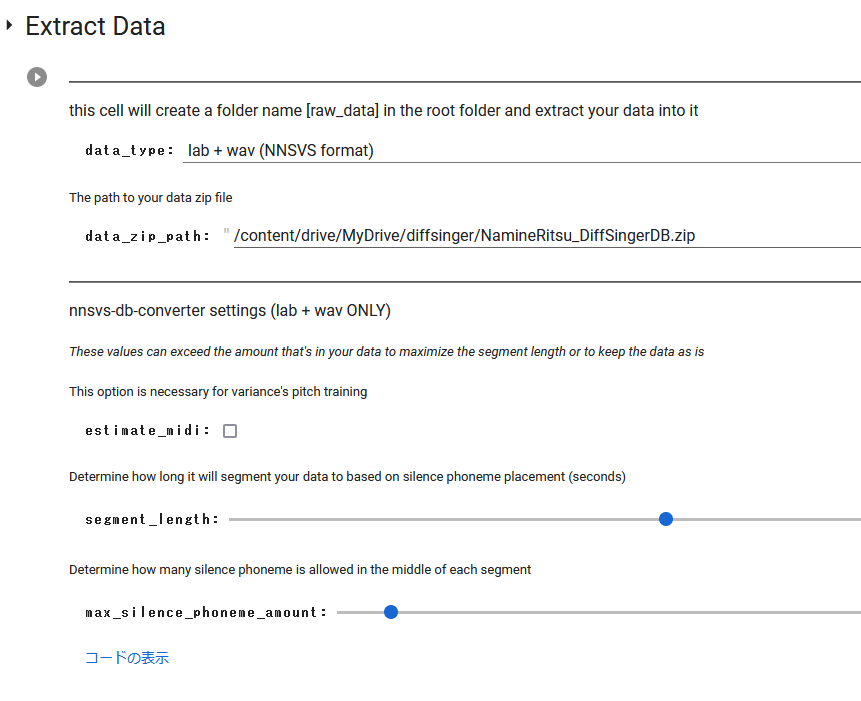
data_type: 【2】の工程を飛ばした場合はNNSVS format、transcroptions.csvを作成した場合はcsv+wavを選ぶ(後者は要検証)
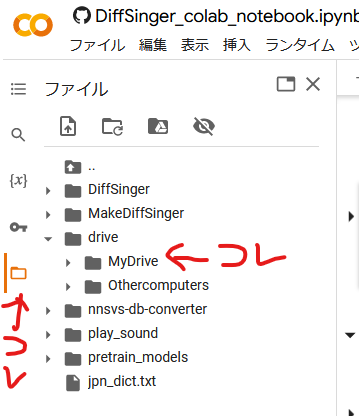
data_zip_path: 左端にフォルダアイコンがあるので(鍵マークの下)それをクリックして、drive→MyDrive→から自分の歌声DBのファイルを見つけて右クリック→パスをコピーし、ここに貼り付ける
他はデフォルト設定のままで実行
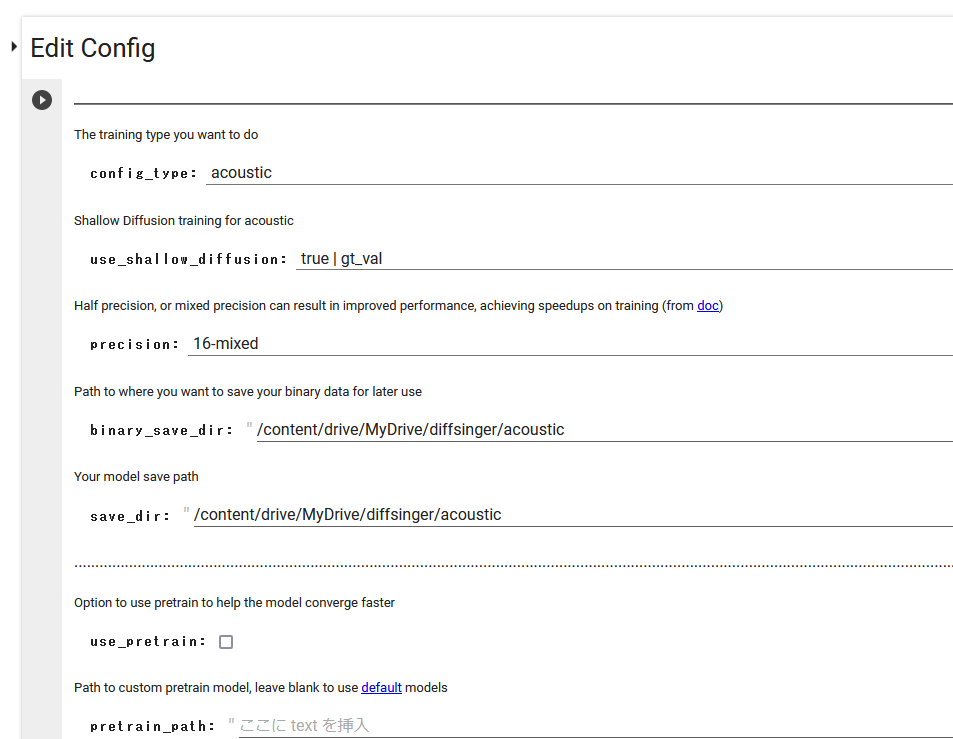
・Edit Config
config_typeはacousticで
binary_save_dir: 適当にdiffsinger用フォルダの下にacousticとかフォルダを作成しておく
save_dir: 適当にdiffsinger用フォルダの下にacousticとかフォルダを作成しておく
use_pretrain: このチェックがデフォルトで入っているのは何故?外します
他はデフォルトで実行
・Preprocess dataを実行
Training
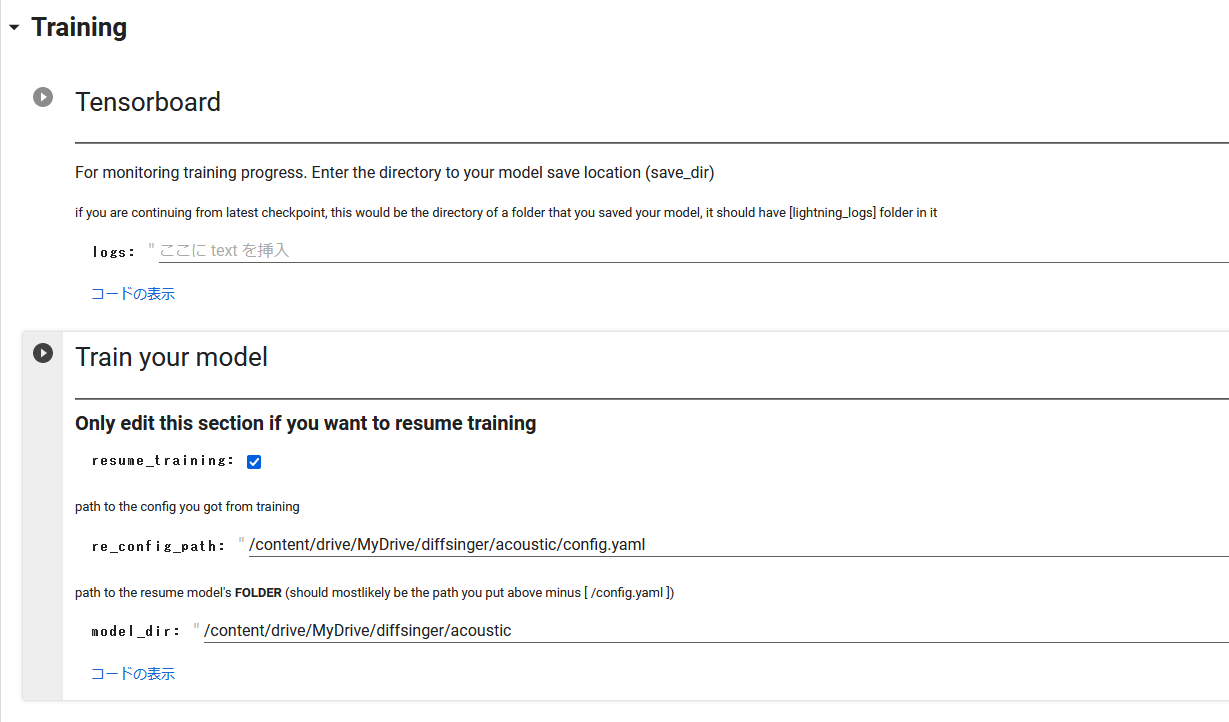
・Tensorboard
そのまま実行
・Train your model
初回はデフォルトで実行
2回目以降、学習の続きを行う場合はresume_trainingにチェックを入れて、acousticのconfig.yamlとmodel__ckpt_steps_xxxxx.ckptがあるフォルダをそれぞれ指定して実行
(3-2) varianceモデルの作成
生成されるモデルのファイル名はacousticと同じため、GoogleDrive上で別フォルダを作っておかないと悲しみを背負います
・Setupをクリック
すぐにGoogleDriveの認証が入るので、出た窓に従って操作してください
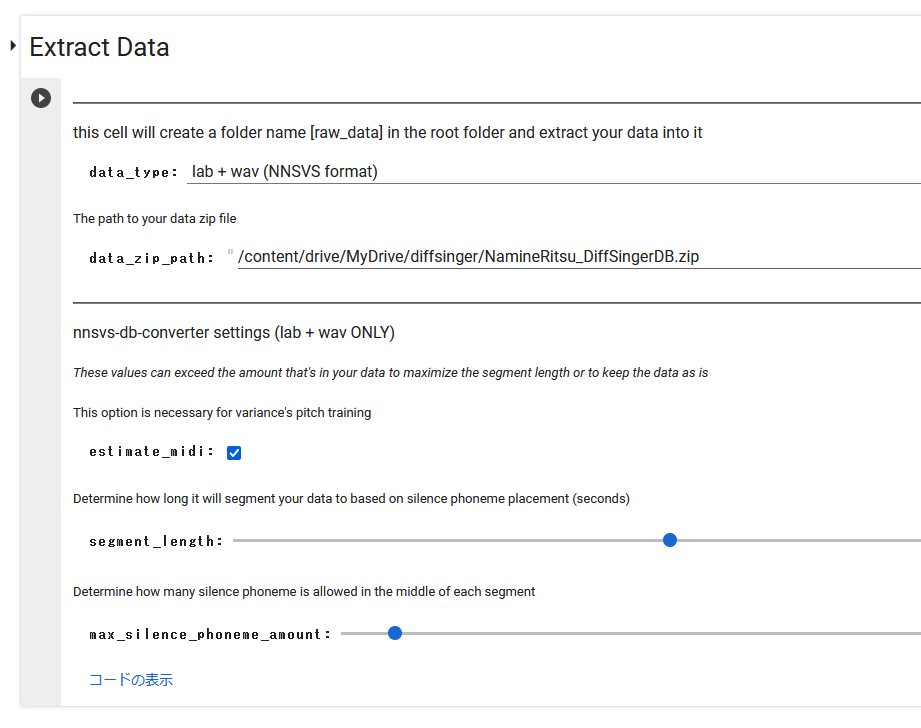
・Extract Dataの設定
data_type: dsファイルを作成していない場合はNNSVS format、【2】に従って作成した場合はds+wavを選択する(後者は要検証)
data_zip_path: acousticの時と同じ
他はデフォルト設定のままで実行
estimate_midi: dsファイルを作成していない場合、このチェックを入れます
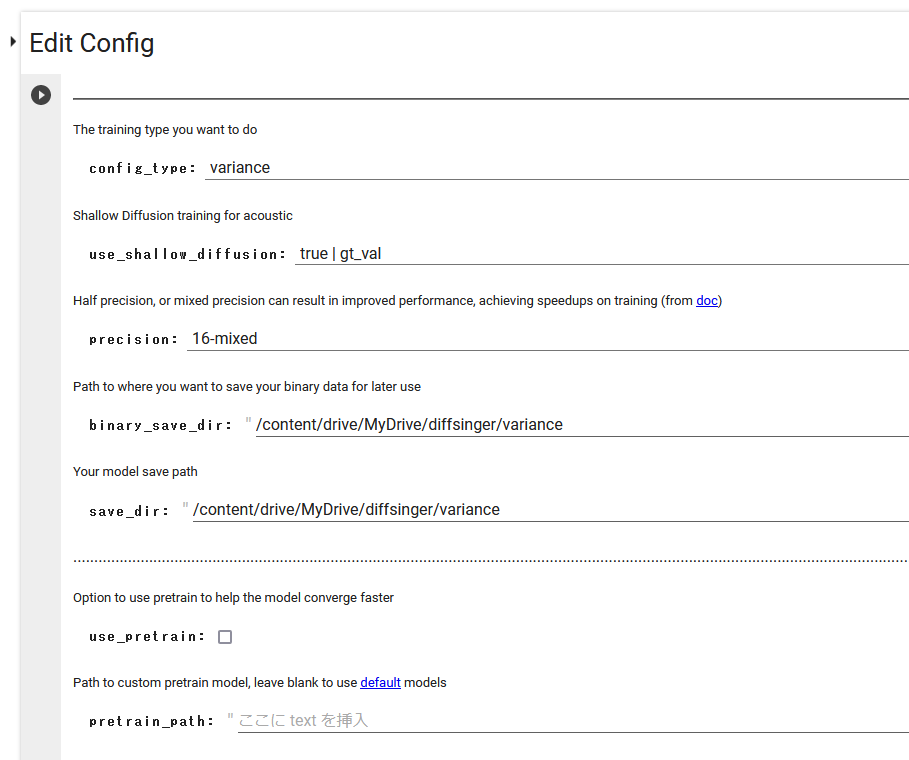
・Edit Config
config_type: variance
binary_save_dir: 適当にdiffsinger用フォルダの下にvarianceとかフォルダを作成しておきす
save_dir: 適当にdiffsinger用フォルダの下にvarianceとかフォルダを作成しておきます
use_pretrain: このチェックがデフォルトで入っているのは何故?外します
他はデフォルトで実行
モデルファイル名はacousticと同様に model__ckpt_steps_xxxxx.ckpt となるため、うっかり同じパスを指定すると上書きされて南無
・Preprocess dataを実行
Training
・Tensorboardを実行
・Train your model
初回はデフォルトで実行
2回目以降、学習の続きを行う場合はresume_trainingにチェックを入れて、varianceのconfig.yamlとmodel__ckpt_steps_xxxxx.ckptがあるフォルダをそれぞれ指定して実行
(3-3)OpenUtauで読み込める形にするっぽい作業
・Drop Speakers from Model (Optional)
デフォルトで実行
ここはスタイルとかの設定が出来るんですかね?わかる方教えてください

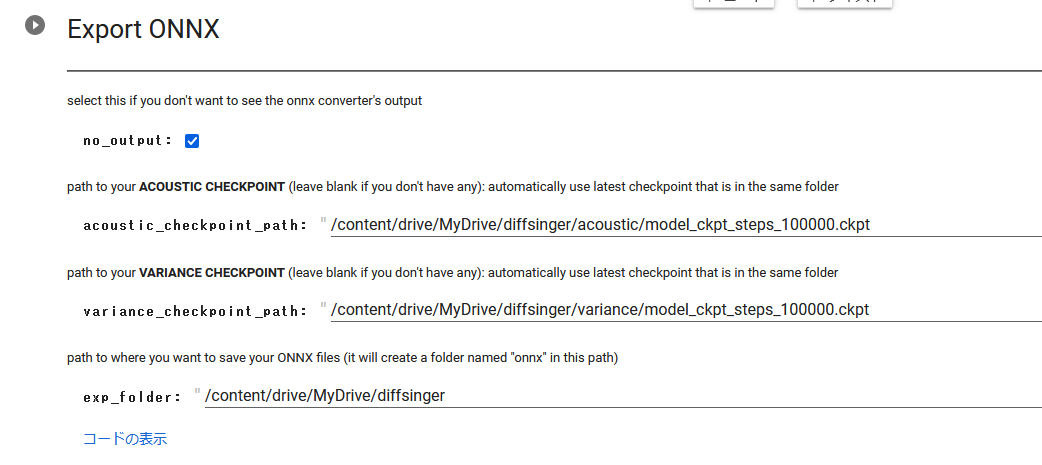
・Export ONNX
acoustic_checkpoint_path: (3-1)で作ったファイルを指定
variance_checkpoint_path: (3-2)で作ったファイルを指定
exp_folder: どこでもいいけどdiffsinger用フォルダをそのまま使っても大丈夫
実行
・Build OpenUtau VB
acoustic_onnx_folder: (3-3)のexpフォルダの下にonnxフォルダが出来ており、更にその下にacousticっていうフォルダが
acoustic_config: acousticのモデルフォルダにあるconfig.yaml
variance_onnx_folder: (3-3)のexpフォルダの下にonnxフォルダが出来ており、更にその下にvarianceっていうフォルダが
variance_config: varianceのモデルフォルダにあるconfig.yaml
dictionary_path: acousticかvarianceのモデルフォルダにあるdictionary.txtのパス(どっちでも同じ)
save_path: どこでもいい
name: キャラクター名(ここでは適当でいい)
これ以降はあとでも追加できるので今入力しなくてもいい
実行するとキャラクター名のzipがsave_pathに出力されます

【4】OpenUtauで音を出す
https://github.com/xunmengshe/OpenUtau/releases/0.0.0.0
上記サイトにて「nsf_hifigan.oudep」をダウンロードし、OpenUtauにD&Dでインストールする
ツール→設定→高度な設定でベータ版をONにする
モデルファイルを解凍し、キャラクター名フォルダをOpenUtauのsingerフォルダに入れる
dsconfig.yamlをテキストエディタで開き、speakers: []の行を削除する
OpenUtauを起動し、シンガーを選択→Diffsinger→作ったキャラクター名を選択
適当に「あ」とか入力して声が出たら成功
※音素名がSPになって上手く行かない場合はdsdur/dsdict.yamlを正しいものに置き換えてください(カノンの落ちる城のツールページで配布しています)